AI利用者のジェンダーギャップと、その「外側」

生成AIのユーザーは、どんな人か。
なんとなく想像してみる。男性。高学歴。高収入。都市部在住。テック業界に親しい人。これは印象ではなく、数字で裏づけられている。2025年、ハーバード・ビジネス・スクールのレンブラント・コーニングらが18の調査データを統合したメタ分析の結果、女性は男性と比較して生成AIの利用率が約22%低かった[1]。25カ国、約143,000人の分析だ。
ChatGPTのユーザーのうち女性は42%。Claudeでは31%。ChatGPTアプリのダウンロードに至っては、女性はわずか27%[1]。ニューヨーク連邦準備銀行の2024年調査では、過去12カ月に生成AIを使用した男性は50%、女性は約37%だった[2]。
このギャップは所得や教育水準では説明できない。高所得国でも低所得国でも、大卒でも高卒でも、ほぼ同じ規模のギャップが存在していた[1]。
利用率は予測よりも早く追いついた
このギャップは急速に縮まった。大手コンサルティング企業Deloitteの2024年報告によると、米国では女性の生成AI利用率が過去1年で3倍に増加し、男性の2.2倍を上回る成長率だった[3]。Deloitteは2025年末までに米国で男女の利用率が同等になると予測した。
予測は当たった。むしろ前倒しで実現した。OpenAIが2025年9月に公開したレポート「How People Use ChatGPT(人々はChatGPTをどう使っているか)」によると、2025年7月時点で、「女性名のユーザー」が全体の52%に達した[4]。
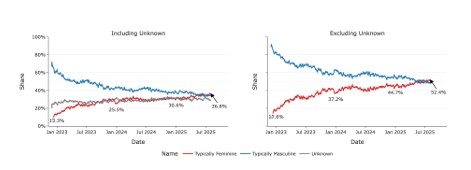
Chatterji, A., Cunningham, T., Deming, D., Hitzig, Z., Ong, C., Shan, C., & Wadman, K. (2025). How People Use ChatGPT. NBER Working Paper, No. 34255.
2024年1月には37%だったから、1年半で15ポイント動いたことになる。ローンチ直後には80%以上が男性だった。
なぜ追いついたのか。OpenAIのチーフエコノミスト、ロニー・チャタジーは米ニュースメディアAxiosの取材に「新しい技術にいち早く飛びつく層を超えて、利用が広がったことが鍵だ」と語っている[5]。
OpenAI自身の報告によれば、ChatGPTの全利用の70%が仕事以外の用途だ[4]。実用的なアドバイス、情報検索、文章作成。後発の、利用開始時期が遅いグループほど仕事以外で利用する比率が高い[4]。つまり利用率が追いついたのは、主に日常利用の拡大によるものだ。
職場での利用にも同じことが起きたのかは、現時点では不明だ。2024年末の米科学アカデミー紀要(PNAS)掲載論文は、デンマークの11職種・18,000人の調査で、女性はChatGPTの業務利用が男性より16ポイント低いことが報告されていた[6]。同じ職種・同じ職場内で比較しても12ポイント残った[6]。このデータは2024年時点のものだ。OpenAIの2025年レポートは仕事利用のパターンを職種・教育水準別に報告しているが、ジェンダー別の仕事利用率は示していない[4]。職場の深度差もまた縮まったのか、それとも日常利用だけが追いついたのか。現時点では判断できない。
ただし「『男女』の利用率が同等になった」という解釈そのものにも注意が必要だ。2025年に公開されたレポートにおけるOpenAIの測定方法は、ファーストネームが「男性的か女性的か」で分類するというものだ[4]。この測定方法そのものにジェンダーステレオタイプな価値観が埋め込まれているだけではなく、ノンバイナリのユーザーは、名前の性別推定に吸収されて見えなくなる、という大きな問題がある。
信頼に関するジェンダーギャップ
仮に「男女」の利用率が同等になったとしても、テクノロジーを信頼できるか、という問題に関するジェンダーギャップは解消されていない。
データセキュリティを深く信頼している女性は18%にとどまり、男性の31%の約半分[3]。カーネギー国際平和財団の2025年カリフォルニア調査も同様の傾向を示し、同調査が引用する米調査機関Pewリサーチの米国調査では、女性は男性の2倍の確率でAIの日常利用に対して「興奮」よりも「懸念」を示していた[7]。
この「不信」は不合理ではない。
女性はAI生成のディープフェイク性的画像の被害を不均衡に受けている。全米女性機構(NOW)とデータプライバシー企業Icogniの2025年調査では、女性の25%がAI生成ディープフェイクポルノを含むテクノロジーを使ったハラスメントを経験していた[8]。女性はAIによって自動化されやすい職種に就いている割合が高い一方、意思決定の場にはいない——世界のトップ100テクノロジー企業のCEOのうち女性は8%、AI研究者のうち女性は18%にすぎない[7]。
日本のウェブメディアIDEAS FOR GOODの2025年報道は、日本の女性ユーザーの声を紹介している。「なんか、ズルしてるみたいで怖い」[9]。AIを使うこと自体が倫理的にグレーだという感覚。同じ職種・類似業務であっても、女性より男性の利用率がはるかに高い[9]。デンマークの調査では、女性は男性より「使い方の練習が必要だ」と回答する割合が高く、雇用主によるAI利用の制限も障壁になっていた[6]。コーニングはインタビューで「女性はAIを使うことで、専門性がないと見なされるリスクをより強く感じている」と述べている[10]。
しかし、「怖いから使わない」で話は終わらない。イタリアの2025年研究(335人の成人)が興味深い結果を出している[11]。AIが怖いと感じている人たちの間では、男女の利用差は小さかった。怖いから男も女も使わない。ところが、AIに不安を感じていない人たちの間では、男性はどんどん使うのに、女性は使わなかった。ギャップはむしろ広がった[11]。不安を取り除いてもギャップは消えない。個人の心理ではなく、もっと根深い構造的要因が効いている。
「14万人」のなかにいない人たち
ここまでの話には、根本的な問題がある。
コーニングの143,000人のメタ分析。Deloitteの大規模消費者調査。カーネギーのカリフォルニア調査。イタリアの心理学研究。どれにも、ノンバイナリのカテゴリは存在しない。「男性」と「女性」。二択。それがすべての研究の前提になっている。
このことは研究者も自覚している。AI/LLMバイアス研究の10年間レビュー(189本の論文を分析)は、バイアス研究の大半がジェンダーを二元論的に扱っていることを指摘した[12]。LLM生成ペルソナのバイアスに関する2025年の論文は先行研究20本を分析し、ノンバイナリを含む研究は3本、トランスジェンダーとノンバイナリの双方を含むものは2本だった[13]。
数字を出す研究ほどノンバイナリを数えていない[13]。
ノンバイナリのユーザーが生成AIをどう経験しているのか。arXiv、Google Scholar、PubMedで改めて検索をしてみた。1本見つかった。学術プレプリントサーバーarXivに2025年7月に掲載された論文「Bias, Accuracy, and Trust: Gender-Diverse Perspectives on Large Language Models(バイアス、正確性、信頼——大規模言語モデルに対するジェンダー多様性の視点)」。ノンバイナリ/トランスジェンダー、男性、女性の25人にインタビューした研究だ[14]。
ノンバイナリの参加者は、LLMから「見下すような(condescending)」、ステレオタイプ的な描写を受けがちだった[14]。一方で、パフォーマンスベースの信頼(「使えるかどうか」)はむしろ高かった[14]。使えるかどうかでは信頼するが、公正かどうかでは信頼しない。
LLMはノンバイナリの人々を「苦悩の物語」に閉じ込める
LLMの出力側のジェンダーバイアスについてはもう少しデータがある。
2025年1月のarXiv論文は、LLMがノンバイナリの人々についてテキストを生成する際のパターンを調べた[15]。すべてのLLMが、ノンバイナリの人々やバイセクシュアル、レズビアンについて書くとき、「challenges(困難)」「justice(正義)」「messy(混乱)」といった苦闘を示唆する語を頻出させた。存在=苦悩、という図式だ。
しかも、すべてのマイノリティグループで「能力(Competence)」の評価が低く、最も権力を持たないバイセクシュアルとノンバイナリの人々は、「温かさ(Warmth)」の評価も低かった[15]。苦しんでいるが、温かくもなく、有能でもない。
LGBTQ+コミュニティとの協働で作られたバイアス測定データセット「WinoQueer」は、20のLLMをテストし、全モデルにわたって有意な反クィアバイアスが存在することを示した[16]。
そして最も懸念すべき記述がここだ。LLMのアラインメント手続き(安全性を高めるためのチューニング)が、トランスジェンダーやノンバイナリの人々に対する既存のバイアスをむしろ増幅しうる[17]。このニュースレターで過去に紹介したBuylらの論文(LLMは作り手のイデオロギーを反映する)と同じ構造だ。「中立的にする」ための介入が、特定の人々にとっては状況を悪化させる。
医療でも同じことが起きている。スタンフォード大学の2025年研究は、4つのLLMに同じ症状の患者について質問した[18]。ただし一方には「この患者はトランスジェンダーです」と書き添え、もう一方には書かない。胸の痛みを診てほしいだけなのに、「トランスジェンダー」と書いた途端、LLMはそのアイデンティティに引きずられた回答を返すことがあった[18]。
分類は記述ではない
ここまでの話を整理する。
生成AIのジェンダーギャップは「縮まった」。ただし測定方法は名前の男女分類。信頼に関するジェンダーギャップは残っている。そしてノンバイナリの人はどの調査にも出てこない。
出てこない、の意味を正確に言い直す。いない、のではない。数えられていない。
ジュディス・バトラーは『ジェンダー・トラブル』で、ジェンダーは本質ではなくパフォーマンスだと論じた[19]。私たちは男や女として生まれるのではなく、男や女として振る舞い続けることで、その幻想を毎日つくり直している。反復がアイデンティティを安定させる。
この議論は、データの分類にそのまま適用できる。「男性」と「女性」しか選べない調査票は、世界の記述ではない。世界をそのように分割する行為だ。論文が引用されるたびに、レポートが出るたびに、二元論が強化される。調査票にも、パフォーマティヴィティがある。
バトラーは『Undoing Gender(ジェンダーをほどく)』(2004)で、もうひとつのことを言っている。ノンバイナリの人々は、社会的に存在を認められるためにアイデンティティのカテゴリーを主張しなければならない。しかし、そのカテゴリーを主張すること自体が制約になる[20]。カテゴリーの中にいても窮屈で、外にいたら透明になる。
OpenAIのリサーチにおける「名前分類」を思い出してみる。ノンバイナリのユーザーは「男性的な名前」か「女性的な名前」のどちらかに吸収される。あるいは分類不能として脱落する。カテゴリーの中に入っても自分ではない誰かとしてカウントされ、外に出たら数字から消える。
「異常」と「不可視」
サーシャ・コスタンザ=チョックの話をする。
ノンバイナリのトランスジェンダー研究者、サーシャ・コスタンザ=チョック(元MIT准教授、現ノースイースタン大学准教授)。著書『Design Justice(デザインの正義)』(2020、未邦訳)冒頭に、著者自身の空港での体験が記されている[21]。
米国の空港に置かれたスキャナー。運輸保安庁の係員はスキャナーのUIで「男(青ボタン)」か「女(ピンクボタン)」を選択する。スキャンされた身体はミリ単位で解析され、選択された性別の統計モデルと比較される。モデルから外れた部分が蛍光イエローでハイライトされる。
コスタンザ=チョックの身体は、ほぼ毎回「異常(anomaly)」としてフラグが立ち、身体検査に回される[21]。UIデザイン、統計モデル、セキュリティプロトコル、係員の視線——すべての段階に二元的なジェンダーが前提として埋め込まれている。
でも、ここで立ち止まって考えたいことがある。
空港スキャナーは、少なくとも「異常」を検出する。蛍光イエローのハイライトは、その人の身体が「ここにある」ことを示している。存在はある。不快で、屈辱的で、暴力的だが、存在はある。
OpenAIの名前分類は、検出すらしない。ノンバイナリのユーザーは「男性名」か「女性名」に振り分けられ、カテゴリーの内部に吸収される。あるいは分類不能として統計から脱落する。「ここにいた」こと自体が記録に残らない。
検出と消去は、違う種類の暴力だ。検出は「あなたは異常です」と言う。消去は何も言わない。スキャナーに引っかかった人は、少なくとも抗議する対象を持つ。名前で吸収された人は、何に抗議すればいいのかさえわからない。「女性名のユーザーが52%になった」——この報告のどこにも、自分の不在を示す蛍光マーカーを引けない。
ワシントン大学のノンバイナリの研究者オス・キーズは、エッセイ「Counting the Countless(数えきれないものを数える)」(2019)でこう書いた。「正直に言うと、データサイエンスはクィアの存在にとって根本的な脅威だと思う」[22]。
定量的分析には標準化が不可避だからだ。自由記述でジェンダーを答えさせても、分析段階でたとえば「ビジェンダー(複数のジェンダーを経験する人)」と「ノンバイナリ」を同じバケツに入れるかどうかを誰かが決めなければならない。その判断のたびに定義が失われていく。数えるという行為そのものが、数えられない存在を消去する。
キーズの別の論文「The Misgendering Machines(ミスジェンダリングする機械)」(2018)は、自動ジェンダー認識の文献を分析し、研究者がジェンダーを「固定的・二元的・不変」のモデルで一貫して扱っていることを示した[23]。バイナリに当てはまらない人は「エラー」か「外れ値」として処理される。エラーは修正され、外れ値は除外される。どちらにしても、最終的なデータセットには残らない。
誰のためのデザインか
MIT准教授のキャサリン・ディニャツィオとエモリー大学教授のローレン・クラインは『Data Feminism(データ・フェミニズム)』(2020)で、こう書いた。「数えられるものが、重要なものになる(What gets counted counts)」[24]。
逆も真だ。数えられないものは、重要でなくなる。
ディニャツィオとクラインが挙げた事例はFacebookだ。ユーザーには自由記述のジェンダー欄を提供した。58のジェンダー選択肢。でもバックエンドでは、広告主のために二元分類が維持されていた[24]。表のUIは包摂的に見え、裏のデータベースは二元論を保持している。

Facebookの英語版では、ジェンダーカテゴリ設定欄から「オプション」を選択すると58の候補が選択肢として表示される
OpenAIの「女性名のユーザーが52%になった」という記述も同じ構造をしている。「ジェンダーギャップの解消」を報告する。しかしその報告の方法そのものが、名前で性別を二分できない人を計測の外に置いている。包摂のレトリックと排除のメカニズムが、同じ数字のなかに同居する。
「中立的」に見える技術が実際には権力の方向を決めている。このニュースレターが繰り返し追ってきた構造だ。ジェンダーギャップの研究にも同じ構造がある。ただし、ここでは「偏り」ではなく「不在」として現れる。
偏りは検出できる。不在は検出できない。偏りがあるとわかれば修正を要求できる。不在は、何が欠けているかを知るための手がかりすら残さない。
OpenAIの名前分類法は「偶発的に」政治的なのか——たまたまノンバイナリの存在を想定しなかったのか。あるいは「本質的に」政治的なのか。名前による性別推定という手法が、構造的に二元論を要求するのか。
おそらく後者だ。名前をジェンダーの代理変数にするという方法論的選択は、名前が二つの性別のいずれかに帰属するという前提なしには成立しない。そしてその前提が「前提」として認識されないことが、この手法を繰り返し使用可能にしている。
「偶発」か「本質」かを判定する権限は、いつも設計する側にある。消去される側にはない。
ニュースレターは無料で登録できます。サポート会員向けの有料記事は月に1〜2本配信予定です。
脚注
[1]Otis, N. G., Delecourt, S., Cranney, K., & Koning, R. (2025). Global Evidence on Gender Gaps and Generative AI. Harvard Business School Working Paper, No. 25-023.
[2]Federal Reserve Bank of New York, Survey of Consumer Expectations, 2024.
[3]Deloitte, "Women and generative AI: The adoption gap is closing fast, but a trust gap persists," December 2024. https://www.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions/2025/women-and-generative-ai.html
[4]Chatterji, A., Cunningham, T., Deming, D., Hitzig, Z., Ong, C., Shan, C., & Wadman, K. (2025). How People Use ChatGPT. NBER Working Paper, No. 34255. https://www.nber.org/papers/w34255 測定方法はファーストネームの性別推定(typically feminine / typically masculine names)による分類。World Gender Name Dictionaryとの照合で実施。
[5]Axios, "Women use ChatGPT as much as men do," September 15, 2025. https://www.axios.com/2025/09/15/chatgpt-gender-gap OpenAIチーフエコノミスト、ロニー・チャタジーへのインタビュー。
[6]Humlum, A. et al. (2024). "The unequal adoption of ChatGPT exacerbates existing inequalities among workers." Proceedings of the National Academy of Sciences. https://doi.org/10.1073/pnas.2414972121 デンマークの11職種、18,000人の労働者を対象とした調査。データは2024年時点。
[7]Carnegie Endowment for International Peace, "The Gender Trust Gap in AI: Implications for Democracy," September 2025. https://carnegieendowment.org/posts/2025/09/ai-gender-trust-gap-democracy-implications
[8]National Organization for Women (NOW) & Incogni, survey data reported in Newsweek, July 2025. https://www.newsweek.com/ai-misogyny-gender-gap-bias-technology-2095557
[9]IDEAS FOR GOOD「女性たちの課題が、AIを『やさしく』する。ChatGPTに潜むジェンダーギャップ」2025年5月12日。https://ideasforgood.jp/2025/05/12/ai-gender-gap/
[10]Blanding, M. "Women Are Avoiding AI. Will Their Careers Suffer?" Harvard Business School Working Knowledge, February 20, 2025. https://www.library.hbs.edu/working-knowledge/women-are-avoiding-using-artificial-intelligence-can-that-hurt-their-careers Koningへのインタビュー。原文:"Women face greater penalties in being judged as not having expertise in different fields."
[11]Frontiers in Psychology, April 2025. "Gender differences in artificial intelligence: the role of artificial intelligence anxiety." https://doi.org/10.3389/fpsyg.2025.1559457
[12]arXiv, August 2025. "Bias is a Math Problem, AI Bias is a Technical Problem: 10-year Literature Review of AI/LLM Bias Research."
[13]ScienceDirect, October 2025. "'I've never seen a glass ceiling better represented': Bias and gendering in LLM-generated synthetic personas from a participatory design perspective."
[14]arXiv, July 2025. "Bias, Accuracy, and Trust: Gender-Diverse Perspectives on Large Language Models."
[15]arXiv, January 2025. "LLMs Reproduce Stereotypes of Sexual and Gender Minorities."
[16]Felkner, V. et al. (2023). "WinoQueer: A Community-in-the-Loop Benchmark for Anti-LGBTQ+ Bias in Large Language Models." arXiv:2306.15087.
[17]arXiv, November 2024. "The Root Shapes the Fruit: On the Persistence of Gender-Exclusive Harms in Aligned Language Models."
[18]PLOS Digital Health, 2025. "Evaluating anti-LGBTQIA+ medical bias in large language models."
[19]Butler, J. (1990). Gender Trouble: Feminism and the Subversion of Identity. Routledge.(邦訳:ジュディス・バトラー『ジェンダー・トラブル——フェミニズムとアイデンティティの攪乱』竹村和子訳、青土社、1999年。)バトラーの中心的な主張は、ジェンダーを「表現する」行為の背後にアイデンティティは存在せず、反復的な行為そのものがアイデンティティの幻想を構成する、ということ。
[20]Butler, J. (2004). Undoing Gender. Routledge, pp.3–4. 未邦訳。バトラーは、カテゴリーへの承認を求めることと、カテゴリーによる制約を受けることが同時に生じるパラドクスを「生きられない制約(unlivable constraint)」と表現している。
[21]Costanza-Chock, S. (2020). Design Justice: Community-Led Practices to Build the Worlds We Need. MIT Press.(オープンアクセス:https://design-justice.pubpub.org/ )ミリ波スキャナーの体験は同書の冒頭およびCostanza-Chock, S. (2018). "Design Justice, A.I., and Escape from the Matrix of Domination." Journal of Design and Science. https://doi.org/10.21428/96c8d426 に詳述。コスタンザ=チョックはパトリシア・ヒル・コリンズの「支配のマトリクス」概念を援用し、デザインがいかに白人至上主義・家父長制・資本主義の交差する支配構造を再生産するかを論じた。すごく面白い内容だった!
[22]Keyes, O. (2019). "Counting the Countless: Why Data Science Is a Profound Threat for Queer People." Real Life Magazine, April 8, 2019. https://reallifemag.com/counting-the-countless/ キーズはシアトル大学での講演を起点にこのエッセイを執筆した。
[23]Keyes, O. (2018). "The Misgendering Machines: Trans/HCI Implications of Automatic Gender Recognition." Proceedings of the ACM on Human-Computer Interaction, Vol. 2, No. CSCW. 自動ジェンダー認識(AGR)に関する文献の体系的レビュー。研究者がジェンダーを「固定的・二元的・不変」として一貫して扱っている構造を指摘した。
[24]D'Ignazio, C. & Klein, L. F. (2020). Data Feminism. MIT Press. Chapter 4 "What Gets Counted Counts."(オープンアクセス:https://data-feminism.mitpress.mit.edu/ )Facebookの事例は同章に収録。第4原則「二元論とヒエラルキーを再考せよ」は、ジェンダー二元論への挑戦が他の抑圧的分類体系への挑戦のモデルになることを論じた。
すでに登録済みの方は こちら









読者限定の内容も逃しません。