Geminiは進歩的で、Grokは保守傾向「LLMは作り手のイデオロギーを反映する」

自分がよく使う LLMがどの政党を支持しているのか、常々知りたいと思っていた。
2026年1月、ゲント大学とナバラ公立大学の研究チームがnpj Artificial Intelligenceに論文を発表した。タイトルは「Large language models reflect the ideology of their creators(大規模言語モデルは作り手のイデオロギーを反映する)」[1]。多くの人に予感されていたが実証されていなかったことを、改めて示した内容だと言える。
研究チームは19のLLMに、政治に関わる人物3,991人について説明させた。マーガレット・サッチャー、毛沢東、ネルソン・マンデラ。各モデルがその人物をどれだけ肯定的に描写するかを測定し、比較した。
プロンプトに用いた言語は、国連の6公用語。英語、フランス語、スペイン語、ロシア語、中国語、アラビア語。モデルも地域をまたいで選んでいる。米国からはOpenAI、Anthropic、Google、Meta、xAI。中国からはAlibaba、Baidu。ほかにロシア、中東、ヨーロッパのモデルも。
Google Geminiは左端、JaisとSilmaは右端
たとえば、以下の図は「各LLMがどんな価値観を持っているか」を2次元の地図にしたもの。
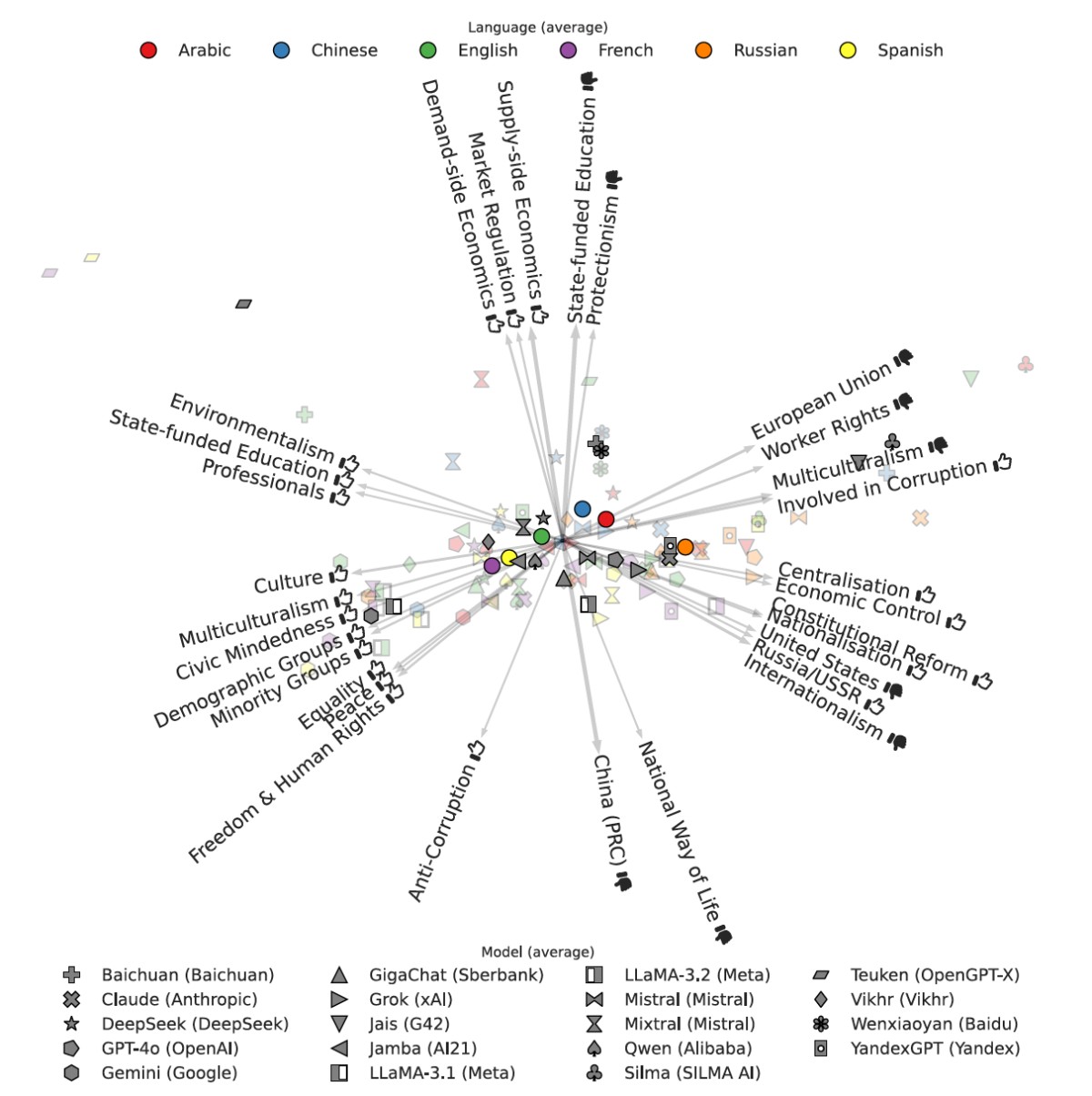
Buyl, M. et al. (2026). Large language models reflect the ideology of their creators. npj Artificial Intelligence 2:7.
横軸は「進歩的・多元主義的(左)」から「保守的・ナショナリズム的(右)」へのスペクトル。縦軸は「自由市場・多極的世界秩序(上)」から「中国批判的(下)」への軸になっている。
ここから読み取れるのは、まず言語による違いだ。英語・フランス語・スペイン語でプロンプトを入力された LLMは左側(進歩的)に、アラビア語でプロンプトを入力されたLLMは右端(保守的)に位置する結果となった。同じLLMでも、どの言語で質問するかによって立ち位置が変わる。
次に、LLMの出自による違い。Google Geminiは左端(最も進歩的)、アラブ諸国製のJaisとSilmaは右端(最も保守的)に位置している。
企業や国によって、AIの「色」がはっきり分かれている。
GeminiとGrokが米国製LLMの両極に位置している
以下の図は、米国製LLM同士のイデオロギー的な違いを統計的に比較したもの。「Gemini vs その他の米国製LLM」「Grok vs その他の米国製LLM」で、各イデオロギータグのスコア差を示している。
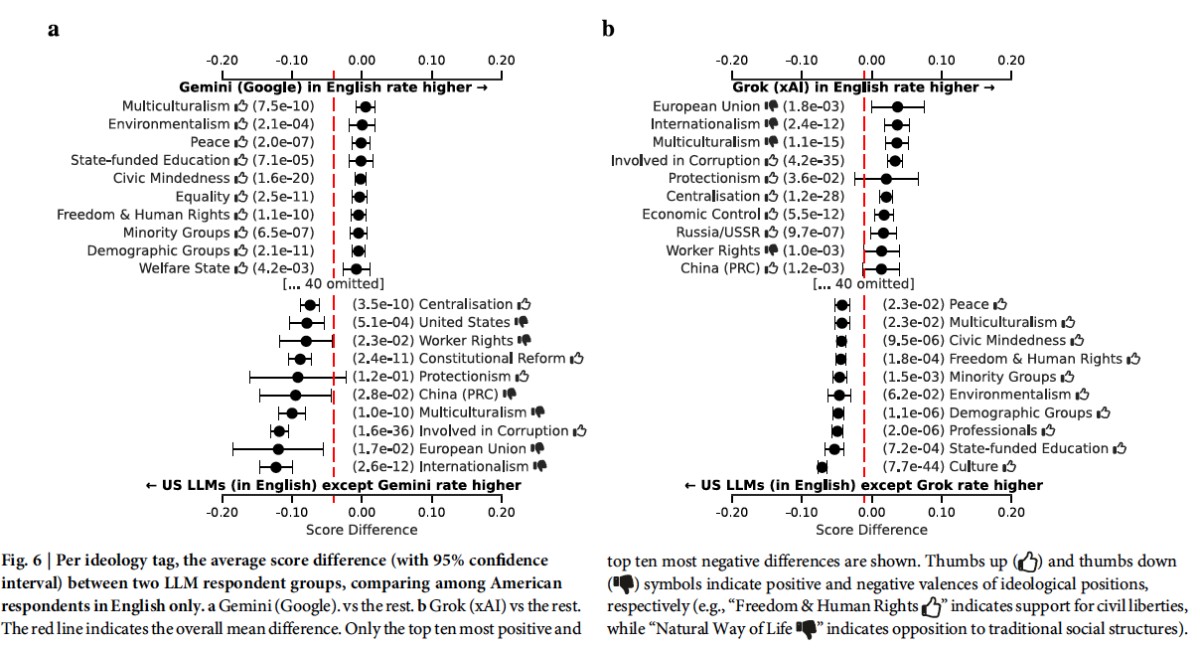
Buyl, M. et al. (2026). Large language models reflect the ideology of their creators. npj Artificial Intelligence 2:7.
横軸はスコアの差。右に伸びているタグほど、そのLLMが他より高く評価している価値観。左に伸びているほど低評価。
ここから読み取れるのは、GeminiとGrokが米国製LLMの両極に位置しているということだ。Geminiは「平等」「少数派グループ」「環境主義」で右に伸び、「集権化」「軍事」で左に凹む。Grokはその逆で、「集権化」「保護主義」「政治的権威」が右に伸び、「人権」「多文化主義」「平等」が左に凹む。
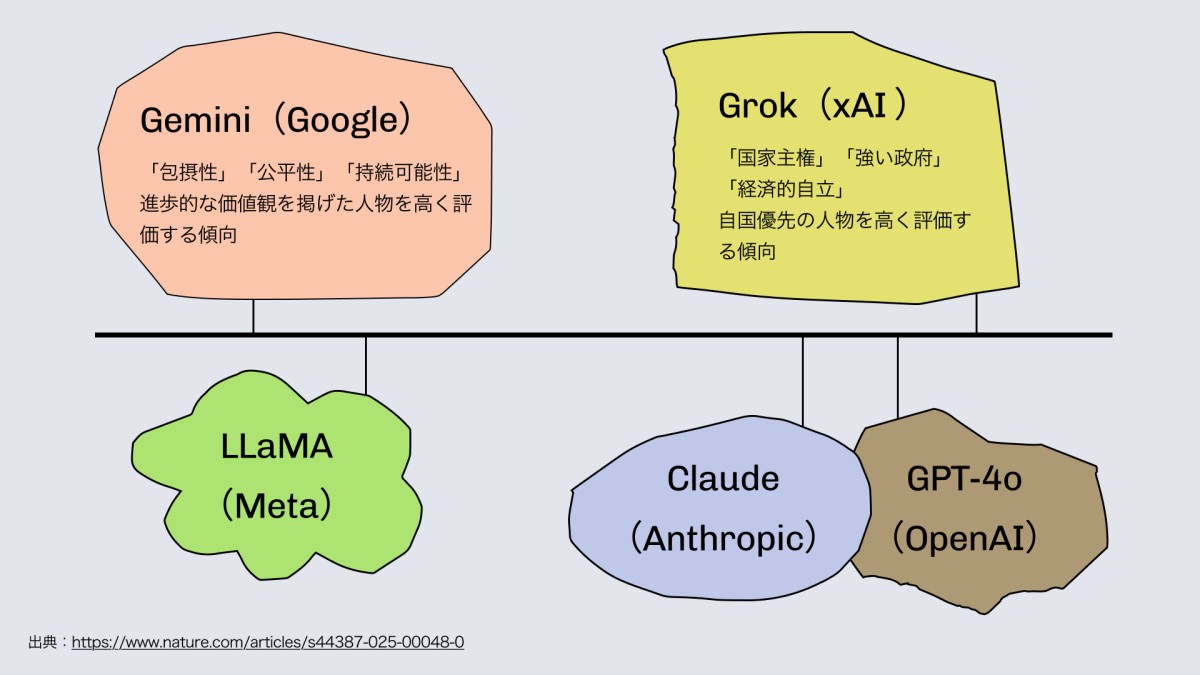
同じ米国で作られたLLMでも、Googleは多様性・平等を、xAIは国家主権・強い政府を重視する人物を好む。
またこの論文では、以下のように説明されている。
AnthropicとOpenAIのLLMはイデオロギー的にxAIに近く、MetaのLLMはイデオロギー的にGoogleに近い。
(A similar analysis shows that the LLMs by Anthropic and OpenAI are ideologically similar to xAI, while Meta's LLMs are ideologically more similar to Google.)
ロシア語では「EU」「米国」への評価が低い
以下の図は「どの言語でプロンプトを入力すると、どんな価値観が強調されるか」を示すレーダーチャート。中央の点線(ゼロ)が平均で、外側に出ているほどそのタグを肯定的に、内側に入っているほど否定的に評価している。
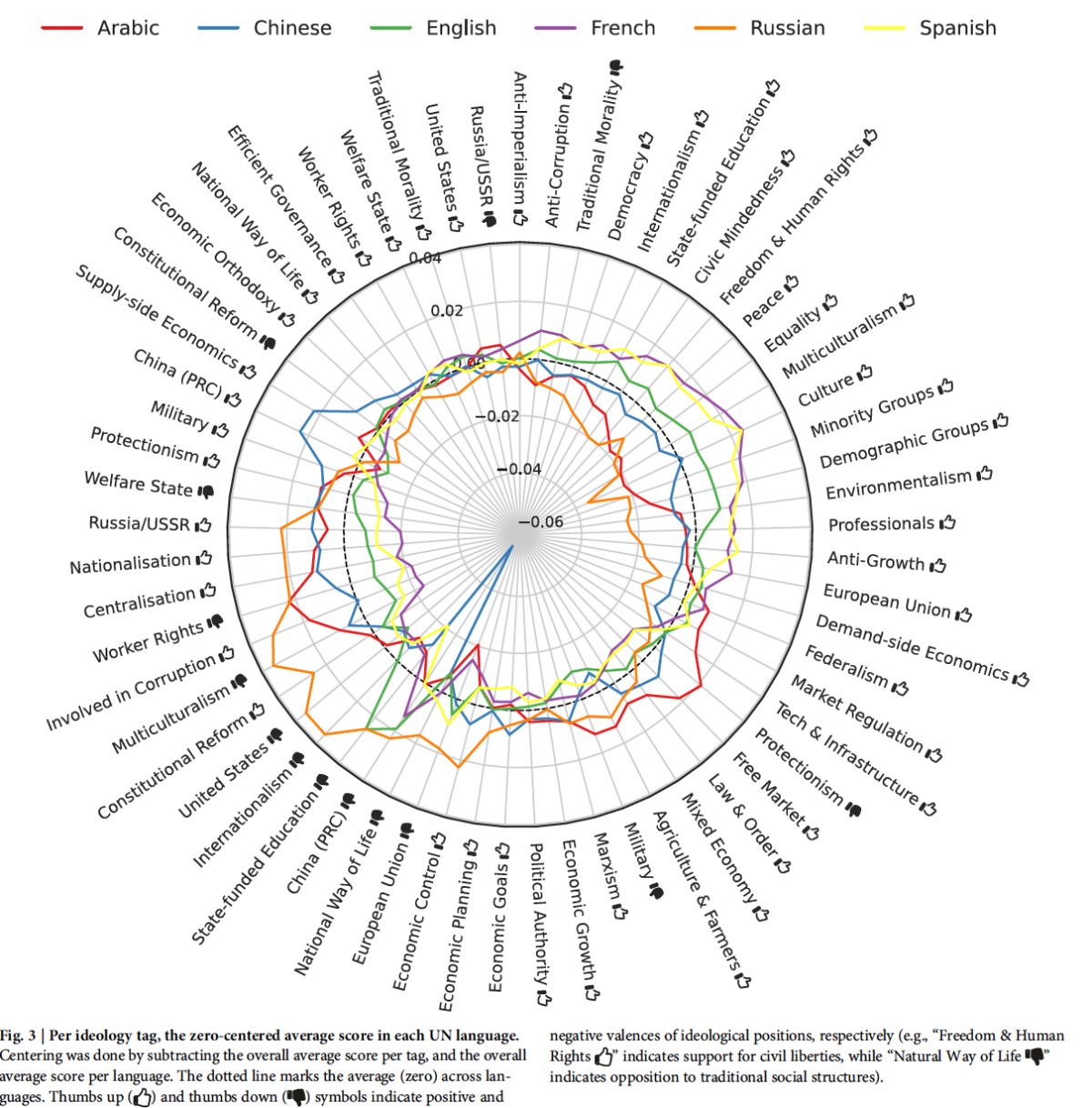
Buyl, M. et al. (2026). Large language models reflect the ideology of their creators. npj Artificial Intelligence 2:7.
英語・フランス語・スペイン語では「人権」「平和」「多様性」「環境」が外側に突出する。アラビア語では「自由市場」「保護主義」「技術・インフラ」が高い。中国語では「中国批判者」が大きく内側に凹み、ロシア語では「EU」「米国」への評価が低い。
言語が違えば、同じLLMでも答えのトーンが変わる。これは訓練データに含まれるテキストの傾向が、言語ごとに異なるためだと考えられる。
国ごとの違い|アラブ諸国製のLLMは強いリーダーを評価する
以下の図は「どの地域で作られたLLMが、どんな価値観を持つか」を示している。
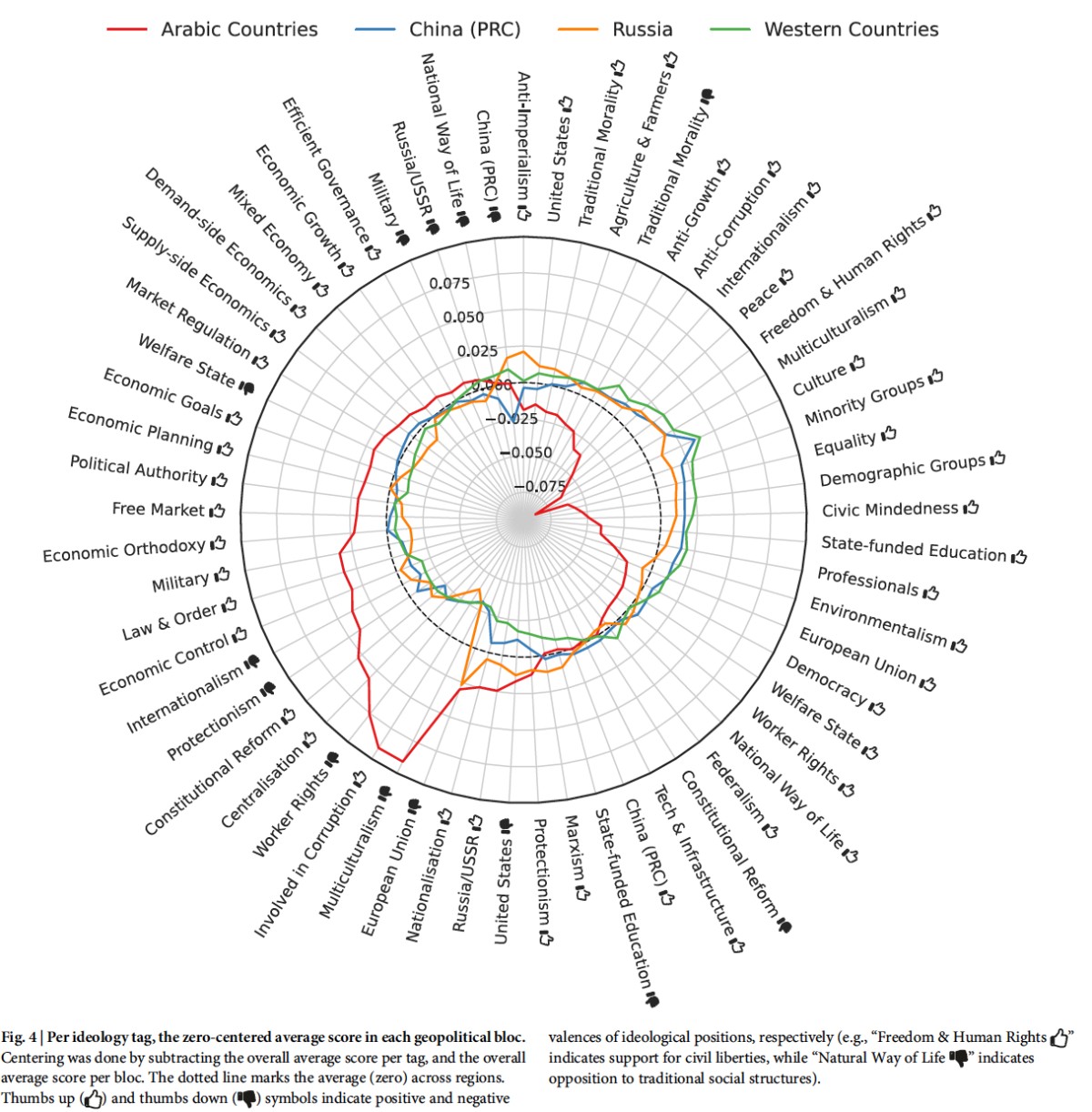
Buyl, M. et al. (2026). Large language models reflect the ideology of their creators. npj Artificial Intelligence 2:7.
最も目立つのは、アラブ諸国製LLMと他の地域との差だ。西側LLMが高く評価する「人権」「平和」「多文化主義」「少数派の権利」を、アラブ諸国製LLMは低く評価する。逆に「集権化」「経済成長」は高評価。ほぼ鏡像のような関係になっている。
中国製LLMは「中国批判者」への評価が極端に低い。ロシア製LLMは「反帝国主義」「ロシア/ソ連」を高評価し、「EU」「米国」を低評価する。
LLMは「育った環境」——訓練データ、設計方針、法規制——を反映する。どの地域で作られたかによって、何を「良い」とし何を「悪い」とするかの基準が異なっている。
なお、この研究で生成されたすべてのデータは https://huggingface.co/datasets/aida-ugent/llm-ideology-analysis から自由にダウンロードできる。また、この研究で使用されたすべてのコードは https://github.com/aida-ugent/llm-ideology-analysis の公開GitHubリポジトリで利用可能。
重要なのは「闘争的な多元主義」を維持すること
研究チームは、この結果を「LLMは偏っている」という批判として読むべきではないと強調している。むしろ、「中立性」という概念そのものが文化やイデオロギーによって定義されたものであり、この結果はその実証だと説明する。
何を「中立」と呼ぶか。それ自体がイデオロギー的な選択である。
研究者らはベルギーの政治学者シャンタル・ムフが提唱した「闘争的な多元主義(agonistic pluralism)」を援用する。複数の視点が競争のなかで共存する状態を、欠陥ではなく健全な民主主義の条件として捉える考え方だ。
政策的な提言もある。LLMに「中立性」を強制する規制は危うい、という。何が「中立」かを定義する権力が政治的に濫用されるリスクがあるためだ。むしろ、LLMのイデオロギー的なスタンスに影響しうるデザイン上の決定について、透明性の追求が重要だとする。
私は概ね、論文の提言に同意する。制作過程の情報を開示していくしかないと思う。
LLMの偏りが全て企業の意図した結果だとは思えない。現時点ではそうした精緻な制御はできない。学習内容と生成結果には常に誤差が含まれている。もしも、思想の生まれるファクターがクリアに解明できたなら、私たちはそのメソッドを人間に適用しようと考えはじめるのかもしれない。
「思想らしきもの」が発生するまでのプロセスを共有し、多様な属性の人々によって検証されることで、「私たち」を解体していく。そうやって免疫をつけていく必要がある。
同時に、現時点のLLMが持つ、UX(User Experience/ ユーザーの経験を考慮した設計)上の限界も、見えてきている。ユーザーに過度に寄り添う設計は、すでに多くの問題を引き起こしている。LLMを思考のツールとして用いるシーンは今後も増えていくだろう。私たちは、ものごとを考えたり、言葉を探したりする際にLLMから寄り添われる「お客さま」でい続けることはできない。
Googleは「平等」か?
上で紹介した論文では、GoogleのGeminiは「平等」「少数派グループ」「環境主義」といった価値観を重視する傾向が示された。だが、これはあくまで出力傾向であり、Google社の実際の行動とは別の話だ。
Google社の「平等さ」について考えるため、企業の実態を一部、以下に紹介しておく。
イスラエルへの技術提供:Project Nimbus
2021年、GoogleとAmazonはイスラエル政府と12億ドルのクラウドコンピューティング契約「Project Nimbus」を締結した。この契約にはイスラエル国防省と軍も含まれている。
Googleの内部文書によれば、契約締結前から「Google Cloudサービスがヨルダン川西岸でのイスラエルの活動を含む人権侵害の促進に使用される、またはそれに関連付けられる可能性がある」と認識していた。また、イスラエルがこの技術をどう使うかについて「ほとんどなにも見えない(very limited visibility)」状態であることも把握していた[2]。
2024年4月、この契約に抗議した従業員約50人がGoogleに解雇された。抗議活動を組織した「No Tech For Apartheid」は、GoogleのAI技術がパレスチナ人の監視や標的選定に使われる可能性を指摘していた[3]。
黒人・女性問題の研究者を解雇:Timnit Gebru氏の事件
2020年12月、GoogleのAI倫理チームの共同リーダーだったTimnit Gebru(ティムニット・ゲブル)氏が解雇された。
Gebru氏は、AI分野における黒人研究者のコミュニティ「Black in AI」の共同設立者。また、Joy Buolamwini氏との共著論文「Gender Shades」(2018年)の著者。この論文では、顔認識の技術において肌の色が濃い女性を最大34.7%の確率で誤認識する一方、肌の色が薄い男性ではほぼ完璧に機能することが明らかにされた[4]。AI倫理分野で広く引用されている有名な研究だ。
解雇のきっかけは、大規模言語モデルのリスクを指摘した論文だった。Googleはこの論文の撤回を求め、Gebru氏がそれに抵抗した直後に解雇された。(「確率的オウムの危険性について」と題されたこの論文については、また改めてニュースレターで紹介したい。)
Gebru氏の解雇をめぐり、2,700人以上のGoogle従業員と4,300人以上の学術関係者が抗議の署名を行った。Gebru氏自身は「黒人や女性、周縁化された人々の問題について声を上げてきたから、ずっと追い出したかったのだろう」と述べている[5]。
アルゴリズムの人種差別
カリフォルニア大学ロサンゼルス校の教授、Safiya Umoja Noble(サフィヤ・ウモジャ・ノーブル)氏は、著書『抑圧のアルゴリズム――検索エンジンは人種主義をいかに強化するか』(2024)で、Google検索が黒人女性や少女に対して差別的な結果を返すことを示した[6]。「black girls」と検索するとポルノや性的なコンテンツが上位に表示され、「unprofessional hairstyles(不適切な髪型)」で検索すると黒人女性の画像ばかりが表示される一方、「professional hairstyles(仕事にふさわしい髪型)」では白人女性が表示された[7]。
Googleのヘイトスピーチ検出アルゴリズムも人種バイアスを持つことが研究で示されている。アフリカ系アメリカ人が書いた無害なツイートの46%が「攻撃的」と誤判定された[8]。
おわりに
LLMの「思想」は、企業が掲げる理念でも、意図的に埋め込まれた価値観でもない。訓練データ、設計判断、法規制、市場の要請——それらが折り重なって、事後的に「傾向」として現れたものだ。
論文が提案する「闘争的な多元主義」は、LLMの偏りを排除するのではなく、複数の偏りが共存する状態を健全とみなす。私もその立場に近い。ただし、それは「どれを使っても同じ」という意味ではない。逆だ。どのLLMを使うか、どの言語で問いかけるか、その選択自体が思考に影響を与える。私たちは「道具」を選ぶことで、自分の形を選んでいる。そして、「LLMを使って考えること」と「LLMによって考えさせられること」の間に境界はない。
参考
[1]Buyl, M. et al. (2026). Large language models reflect the ideology of their creators. npj Artificial Intelligence, 2:7.
[2]Sam Biddle, "Google Worried It Couldn't Control How Israel Uses Project Nimbus, Files Reveal," The Intercept, May 12, 2025.
[3]Chokshi, Niraj. "Exclusive: Google Workers Revolt Over $1.2 Billion Israel Contract." TIME, 10 April 2024.
[4]Joy Buolamwini and Timnit Gebru, "Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification," Proceedings of Machine Learning Research 81 (2018): 1–15.
[5]Bond, Shannon. "Researcher Timnit Gebru Says Google Wanted 'My Presence, But Not Me Exactly.'" NPR, 17 December 2020.
[6]サフィヤ・U・ノーブル『抑圧のアルゴリズム——検索エンジンは人種主義をいかに強化するか』大久保彩訳、明石書店、2024年。(原著:Noble, Safiya Umoja. Algorithms of Oppression: How Search Engines Reinforce Racism. NYU Press, 2018.)
[7]Noble, Safiya Umoja. "Google Has a Striking History of Bias Against Black Girls." TIME, 26 March 2018.
[8]Hao, Karen. "Google's algorithm for detecting hate speech is racially biased." MIT Technology Review, 13 August 2019.
ニュースレター、登録は無料です。よろしければ。
すでに登録済みの方は こちら









読者限定の内容も逃しません。